HTTP stands for Hypertext Transfer Protocol, a stateless application- level protocol for distributed, collaborative, hypertext information systems. It was initiated by Tim Berners-Lee in 1989 at the European Organization for Nuclear Research (CERN).
You can check out the specs for HTTP on the W3C website.
The idea is that hypertext is text that contains hyperlinks to other nodes containing text, i.e. websites and web pages, with HTTP being the protocol to do this. HTTP is a request and response protocol – for example, web pages request information from a website, and the website responds with the web page in HTML or other forms of content. This can be extended such that it is not just web pages requesting content, and the type of content requested can vary (e.g. JSON, XML, media).
HTTP defines verbs that define the requested action from the web page or initiator of the request.
HTTP methods include:
- GET
- HEAD
- POST
- PUT
- DELETE
- TRACE
- OPTIONS
- CONNECT
- PATCH
HTTP is stateless in that each command is executed independently.
HTTP returns status and error codes. A list of the errors can be found on the W3C site here. The classes of error codes include:
- 100s – Informational
- 200s – Success
- 300s – Redirection
- 400s – Client error
- 500s – Server error
Some common examples of these include:
- 400 Bad Request
- 401 Unauthorized
- 403 Forbidden
- 404 Not Found
- 500 Internal Server Error
Using built in tools in the web browser, we can see the request and response headers:
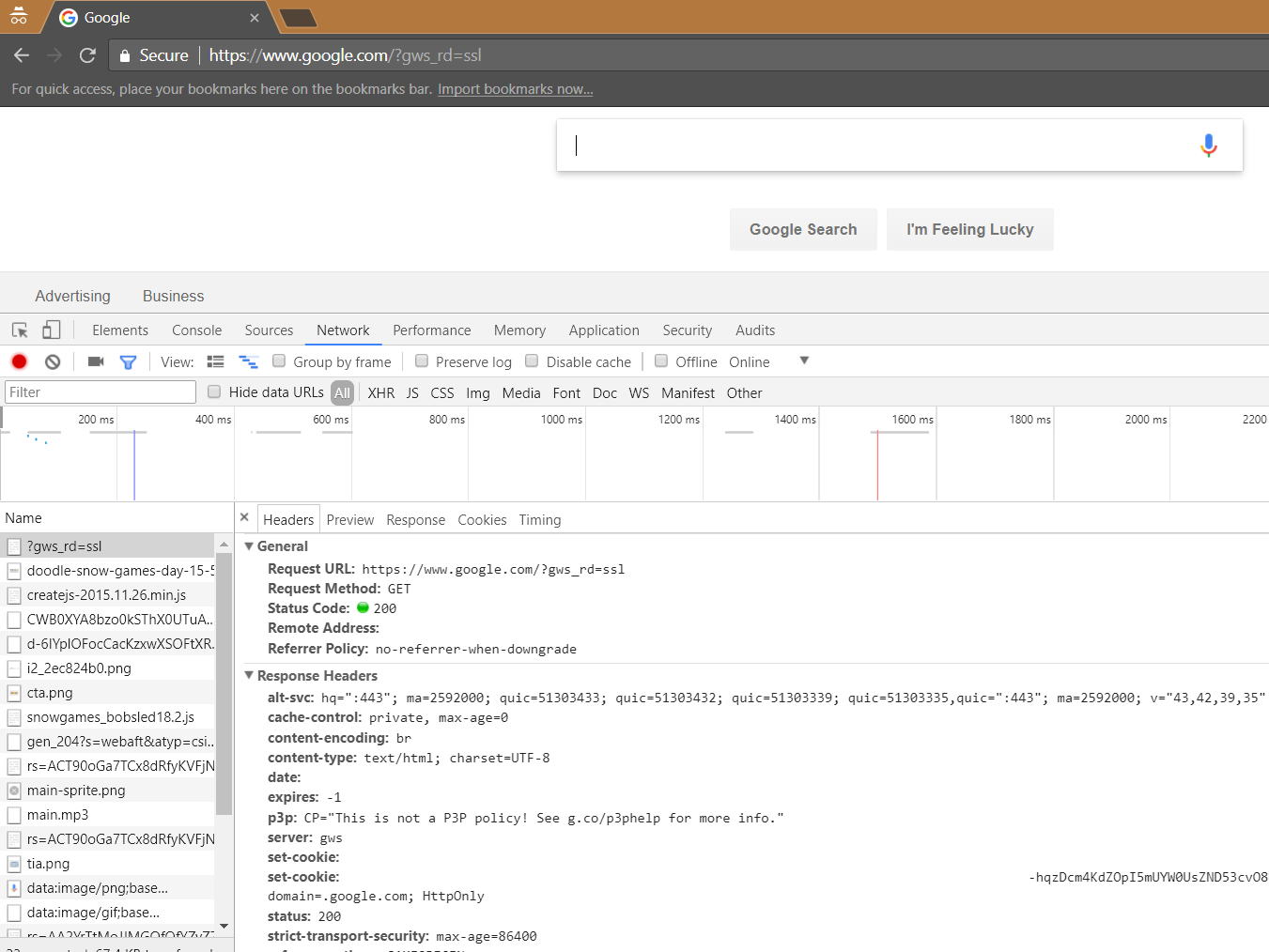
And the cookies:

I AM SPENDING MORE TIME THESE DAYS CREATING YOUTUBE VIDEOS TO HELP PEOPLE LEARN THE MICROSOFT POWER PLATFORM.
IF YOU WOULD LIKE TO SEE HOW I BUILD APPS, OR FIND SOMETHING USEFUL READING MY BLOG, I WOULD REALLY APPRECIATE YOU SUBSCRIBING TO MY YOUTUBE CHANNEL.
THANK YOU, AND LET'S KEEP LEARNING TOGETHER.
CARL
